



排序
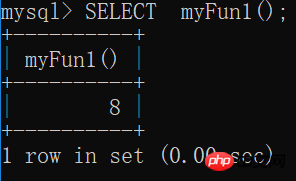
Mysql函數 的相關講解
含義:一組預先編譯好的SQL語句的集合,可以理解成批處理語句作用: 提高代碼的重用性 簡化操作 減少了編譯次數并且減少了和數據庫服務器的連接次數,提高了效率 和存儲過程的區別:存儲過程:...

Java調用Python Spark程序卡死:如何解決Runtime.getRuntime().exec()阻塞問題?
java調用python代碼卡住問題分析與解決 在使用java調用python代碼的過程中,經常會遇到一些棘手的問題,例如程序卡住無法繼續執行。本文將針對一個具體的案例進行分析,并提供相應的解決方案。 ...

apache spark 是什么
Spark是一個基于內存計算的開源的集群計算系統,目的是讓數據分析更加快速。Spark非常小巧玲瓏,由加州伯克利大學AMP實驗室的Matei為主的小團隊所開發。使用的語言是Scala,項目的core部分的代...

Python中如何實現詞頻統計?
在python中實現詞頻統計可以通過以下步驟進行:1. 使用字典統計詞頻,2. 改進代碼處理大小寫和標點符號,3. 使用生成器處理大文件,4. 過濾停用詞,5. 優化性能和擴展性。每個步驟都提供了不同...

java主要是干嘛的 Java在實際開發中的主要用途解析
java 主要用于構建桌面應用、移動應用、企業級解決方案和大數據處理。1. 企業級應用:通過 java ee 支持復雜應用,如銀行系統。2. web 開發:使用 spring、hibernate 簡化開發,spring boot 快...

Kafka在Linux上的備份策略是什么
本文介紹在Linux系統上針對Kafka的備份策略,主要涵蓋全量備份和增量備份兩種方式。 一、全量備份 全量備份是指將整個Kafka集群的數據完整復制到另一存儲位置。 實現方法通常是利用kafka-consol...

實現Oracle數據庫與Kafka的數據交互和同步
實現oracle數據庫與kafka的數據同步需要以下步驟:1)使用oracle goldengate或cdc捕獲oracle數據庫變化;2)通過kafka connect將數據轉換并發送到kafka;3)使用kafka消費者進行數據消費和處理...

Kafka在Linux上的備份與恢復方法
本文介紹幾種在Linux系統上備份和恢復Kafka數據的常用方法,幫助您有效保護寶貴數據。 方法一:利用Kafka自帶工具 此方法利用Kafka自帶的腳本實現備份和恢復。 全量備份: 使用kafka-dump-log.sh...

Linux Kafka如何與其他中間件協同工作
Linux Kafka,作為一款高性能分布式流處理平臺,在構建實時數據流應用方面表現卓越。其與其他中間件的集成,擴展了其應用范圍,提升了數據處理能力。以下是一些常見的集成方案及應用場景: Kafk...

什么是apache kafka數據采集
什么是apache kafka數據采集? Apache Kafka - 介紹 Apache Kafka起源于LinkedIn,后來成為2011年的開源Apache項目,然后在2012年成為Apache的一流項目。Kafka以Scala和Java編寫。Apache Kafka...

laravel spark是什么意思
在laravel中,spark是一個實驗性的項目,用于構建面向企業的軟件即服務應用;主要功能包括成員管理、用戶角色管理以及通過Stripe計費等,也就是將企業應用中的一些常見功能模塊化。 本文操作環...