



排序

Debian Hadoop任務執行流程是怎樣的
在Debian系統上運行Hadoop任務,需要經歷以下關鍵步驟: 1. 環境準備: 首先,搭建并配置Hadoop集群,這包括確定節點數量、硬件資源(內存、CPU等)以及網絡連接狀況。 其次,安裝并配置Hadoop軟...

Debian上Hadoop日志如何分析
在debian系統上分析hadoop日志可以通過多種方式進行操作: 日志文件所在位置 Hadoop日志文件通常存儲在 /logs 目錄下,這些日志涵蓋了NameNode和DataNode的記錄,以及與MapReduce作業和HDFS相關...

Hadoop Linux環境如何進行維護
在Hadoop Linux環境中進行維護,主要包括以下幾個方面: 1. 系統更新與補丁管理 定期更新操作系統:確保Linux系統始終保持最新狀態,安裝所有必要的安全補丁和更新。 監控軟件包狀態:利用yum或...

HDFS網絡傳輸優化有哪些方法
HDFS(Hadoop Distributed File System)網絡傳輸性能的優化是大數據架構中至關重要的環節,其目標在于提升數據傳輸速度、降低延遲以及減少帶寬占用。以下是幾種實用的優化策略: 網絡硬件層面...

如何在CentOS和Fedora上安裝Yarn
yarn是一個用于node.js應用程序的高級包管理軟件。它是任意一個其他nodejs包管理器的快速、安全和可靠的替代方案。本篇文章包含三種在centos,redhat和fedora系統上安裝yarn的方法。 1、使用NPM...

手把手教你怎么在VSCode中配置并使用Vue
本篇文章給大家介紹一下在vscode中搭建并配置vue環境,使用vue的方法,希望對需要的朋友有所幫助! Vue.js是一個流行的 JavaScript 庫,用于構建 Web 應用程序用戶界面,Visual Studio Code 內...

在Vue中如何使用AntV X6庫動態展示組織架構圖?
Vue.js動態組織架構圖展示 本文介紹如何在vue.js應用中,利用antv x6庫動態生成和展示組織架構圖,并根據后端返回的數據進行實時更新。 AntV X6是一個功能強大的圖形庫,適用于構建各種類型的圖...
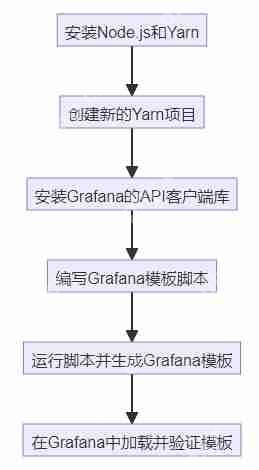
使用Yarn創建Grafana模板的完整指南
在本文中,我將引導你一步步完成使用yarn生成grafana模板的過程。grafana是一款開源的數據可視化工具,我們可以利用它來創建各種儀表板,以便更有效地監控和展示數據。請跟隨我一起完成這個過程...

如何在CentOS上配置HDFS數據本地化
在centos上設置hdfs(hadoop分布式文件系統)數據本地化,可以通過以下步驟進行: 1. 安裝Hadoop 首先,確認你已經在CentOS系統上安裝了Hadoop。如果未安裝,請參考Hadoop的官方指南進行安裝。 ...

如何在Linux上部署Hadoop集群
alt='如何在linux上部署hadoop集群' /> 在Linux上部署Hadoop集群是一個相對復雜的過程,需要多個步驟和配置。以下是一個基本的指南,假設你使用的是Ubuntu 24.2作為操作系統。 環境準備 選擇...
Debian Hadoop任務執行流程是什么
hadoop任務執行流程主要包括以下幾個步驟: 提交作業:用戶在客戶端機器上使用Hadoop提供的命令行工具或API,構建任務的執行環境并將任務提交到YARN(Hadoop的資源管理器)。 資源申請:YARN收...