



排序

python永久免費版入口 python免費版看電影入口地址
Python,作為一門廣泛應用于科學計算、數據分析、機器學習等領域的編程語言,其開源特性使得它在全球范圍內備受歡迎。然而,Python不僅是程序員的得力工具,它還可以為影視愛好者提供一個全新的...

怎么生成網站地圖xm!
生成網站地圖(xml格式)的方法包括:1. 使用在線工具或插件,如yoast seo;2. 手動生成xml文件;3. 使用編程語言如python自動生成。網站地圖幫助搜索引擎更好地索引網站內容,提升seo表現。 引...

python干什么的 舉例 python實際應用案例
python 在數據科學、網絡開發、自動化、機器學習和人工智能等領域廣泛應用。1) 數據科學和機器學習:python 提供了如 pandas、numpy、scipy、scikit-learn 和 tensorflow 等強大庫,適用于數據...

怎樣用Python爬取網頁數據?
python是爬取網頁數據的首選工具。使用requests和beautifulsoup庫可以輕松發送http請求和解析html內容。1)發送http請求:使用requests庫獲取網頁內容。2)解析html:使用beautifulsoup庫提取數...
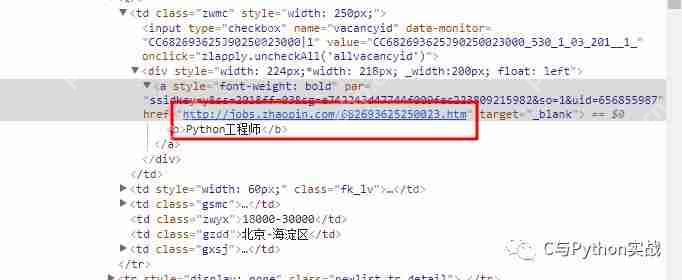
Python爬蟲之六:智聯招聘進階版
運行平臺: windows python版本: python3.6 ide: sublime text 其他工具: chrome瀏覽器0、寫在前面的話本文是基于基礎版上做的修改,如果沒有閱讀基礎版,請移步 Python爬蟲之五:抓取智聯招...

Python人馬獸系列是啥 Python人馬獸系系列主要內容有哪些
“Python 人馬獸系列”沒有確切定義,可能與神話、游戲、庫戲稱、教育資源或拼寫錯誤有關。以下是可能相關的Python庫:1. NumPy/SciPy用于科學計算,2. Matplotlib/Seaborn用于數據可視化,3. S...

python爬蟲需要學哪些東西 爬蟲必備知識清單
要成為python爬蟲高手,你需要掌握以下關鍵技能和知識:1. python基礎,包括基本語法、數據結構、文件操作;2. 網絡知識,如http協議、html、css;3. 數據解析,使用beautifulsoup、lxml等庫;4...

Python中如何模擬瀏覽器操作?
在python中模擬瀏覽器操作主要使用selenium和beautifulsoup。1.安裝selenium:pip install selenium。2.選擇并配置瀏覽器驅動程序,如chromedriver。3.使用selenium啟動瀏覽器并訪問網頁。4.模...

Python中如何獲取網頁的HTML內容?
在python中獲取網頁的html內容可以使用requests庫。具體步驟包括:1. 使用requests.get()發送get請求獲取html內容;2. 檢查http狀態碼,處理錯誤情況;3. 設置用戶代理和請求超時;4. 使用beaut...

Python中怎樣實現Web爬蟲?
用python實現web爬蟲可以通過以下步驟:1. 使用requests庫發送http請求獲取網頁內容。2. 利用beautifulsoup或lxml解析html提取信息。3. 借助scrapy框架實現更復雜的爬蟲任務,包括分布式爬蟲和...