



排序

Python的BeautifulSoup庫怎么使用?
beautifulsoup庫在python中用于解析html和xml文件。它提供了靈活的解析功能和人性化的數據操作方式。使用步驟包括:1) 創建beautifulsoup對象并選擇解析器,如html.parser或lxml;2) 使用find_a...

Python中如何解析HTML文檔?
在python中高效解析html文檔可以使用beautifulsoup和lxml庫。1) beautifulsoup適用于處理不規范的html,提供簡單導航和搜索功能,但解析速度較慢。2) lxml解析速度快,支持xpath查詢,但對不規...

Python人馬獸系列是啥 Python人馬獸系系列主要內容有哪些
“Python 人馬獸系列”沒有確切定義,可能與神話、游戲、庫戲稱、教育資源或拼寫錯誤有關。以下是可能相關的Python庫:1. NumPy/SciPy用于科學計算,2. Matplotlib/Seaborn用于數據可視化,3. S...

HTML轉換成DOCX文件的方法
使用python的python-docx和beautifulsoup庫可以實現html到docx的轉換。1) 使用beautifulsoup解析html內容。2) 利用python-docx生成和操作docx文件。3) 遍歷html元素并添加到docx文檔中。4) 保存...

如何在Python中使用BeautifulSoup?
使用beautifulsoup解析html和xml文檔的步驟如下:1. 安裝beautifulsoup:使用命令“pip install beautifulsoup4”。2. 導入beautifulsoup:在代碼中使用“from bs4 import beautifulsoup”。3. ...
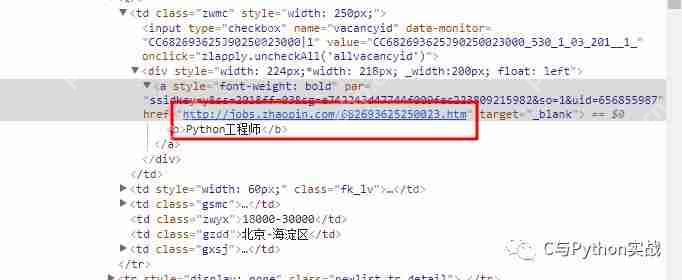
Python爬蟲之六:智聯招聘進階版
運行平臺: windows python版本: python3.6 ide: sublime text 其他工具: chrome瀏覽器0、寫在前面的話本文是基于基礎版上做的修改,如果沒有閱讀基礎版,請移步 Python爬蟲之五:抓取智聯招...

如何轉換HTML為JSON?數據提取簡易教程
將html轉換為json需解析文檔、提取數據并結構化輸出。1.選擇合適的解析工具,如python的beautiful soup或javascript的cheerio;2.加載html文檔內容;3.使用css選擇器或xpath定位目標元素;4.提...

怎樣在Python中處理爬取數據?
在python中處理爬取數據主要使用beautifulsoup解析html、json模塊處理json和xml.etree.elementtree解析xml。1) 使用beautifulsoup從html中提取標題和段落。2) 用json.loads()解析json數據。3) ...

怎樣用Python爬取網頁數據?
python是爬取網頁數據的首選工具。使用requests和beautifulsoup庫可以輕松發送http請求和解析html內容。1)發送http請求:使用requests庫獲取網頁內容。2)解析html:使用beautifulsoup庫提取數...

HTML與XML之間的轉換方法
html與xml之間的轉換可以通過解析和生成過程實現。1) 使用beautifulsoup解析html并用xml.etree.elementtree生成xml。2) 使用xml.etree.elementtree解析xml并生成html。需要注意標記語言的差異和...